install.packages("scitb")scitb-快速生成基线表一
R包
表格
R包介绍
scitb是一个专门用于基线表开发的包,相较于tableone scitb具有更好使用,导出方便,快速设置的优点
R包安装
R包使用
导入示例数据
导入数据prematurity,:low 是否是小于2500g早产低体重儿,age 母亲的年龄,lwt 末次月经体重,race 种族,smoke孕期抽烟,ptl 早产史(计数),ht 有高血压病史,ui 子宫过敏,ftv 早孕时看医生的次数bwt 新生儿体重数值
library(scitb)
library(bruceR)
bruceR (v2025.11)
Broadly Useful Convenient and Efficient R functions
Packages also loaded:
✔ dplyr ✔ data.table
✔ tidyr ✔ emmeans
✔ stringr ✔ lmerTest
✔ forcats ✔ effectsize
✔ ggplot2 ✔ performance
✔ cowplot ✔ interactions
Main functions of `bruceR`:
cc() Describe() TTEST()
add() Freq() MANOVA()
.mean() Corr() EMMEANS()
set.wd() Alpha() PROCESS()
import() EFA() model_summary()
print_table() CFA() lavaan_summary()
For full functionality, please install all dependencies:
install.packages("bruceR", dep=TRUE)
Online documentation:
https://psychbruce.github.io/bruceR
To use this package in publications, please cite:
Bao, H. W. S. (2021). bruceR: Broadly useful convenient and efficient R functions (Version 2025.11) [Computer software]. https://doi.org/10.32614/CRAN.package.bruceRdata <- prematurity
head(data,5) id low age lwt race smoke ptl ht ui ftv bwt
1 85 0 19 182 black nonsmoker 0 0 1 0 2523
2 86 0 33 155 other nonsmoker 0 0 0 3 2551
3 87 0 20 105 white smoker 0 0 0 1 2557
4 88 0 21 108 white smoker 0 0 1 2 2594
5 89 0 18 107 white smoker 0 0 1 0 2600生成描述性表1
首先定义变量
为什么这里要定义变量,而不在基线表函数里直接引入字符向量,这是为了有良好的编程习惯。先从构建函数框架开始,最后函数调用,后续无论是修改变量还是增删变量都会很清晰
allVars<-c("low","age","lwt","race","smoke","ptl","ht","ui","ftv","bwt")
fvars<-c("low","race","smoke","ptl","ht","ui","ftv")
strata<-c("bwt")生成基线表
data_neat <- data |>
mutate(
race = as.factor(race),
smoke = as.factor(smoke)
)
tab0<-scitb1(vars=allVars,fvars=fvars,strata=strata,data=data_neat) Min 33.33333% 66.66667% Max
709.000 2598.000 3283.667 4990.000 Strata is treated as a continuous variable.tab0 Characteristic G.0 G.1
"N" "63" "63"
d1 "age" "22.00 (19.50-25.00)" "23.00 (19.00-28.00)"
d1 "lwt" "120.00 (105.00-131.00)" "120.00 (109.50-132.50)"
d1 "bwt" "2126.24±394.60" "2969.94±190.20"
d2 "low" " " " "
"0" " 4 (6.35%)" "63 (100.00%)"
"1" "59 (93.65%)" " 0 (0.00%)"
d2 "race" " " " "
"black" "12 (19.05%)" " 8 (12.70%)"
"other" "26 (41.27%)" "25 (39.68%)"
"white" "25 (39.68%)" "30 (47.62%)"
d2 "smoke" " " " "
"nonsmoker" "31 (49.21%)" "39 (61.90%)"
"smoker" "32 (50.79%)" "24 (38.10%)"
d2 "ptl" " " " "
"0" "45 (71.43%)" "58 (92.06%)"
"1" "16 (25.40%)" " 4 (6.35%)"
"2" " 2 (3.17%)" " 1 (1.59%)"
"3" " 0 (0.00%)" " 0 (0.00%)"
d2 "ht" " " " "
"0" "56 (88.89%)" "61 (96.83%)"
"1" " 7 (11.11%)" " 2 (3.17%)"
d2 "ui" " " " "
"0" "47 (74.60%)" "54 (85.71%)"
"1" "16 (25.40%)" " 9 (14.29%)"
d2 "ftv" " " " "
"0" "37 (58.73%)" "32 (50.79%)"
"1" "12 (19.05%)" "15 (23.81%)"
"2" " 8 (12.70%)" "13 (20.63%)"
"3" " 5 (7.94%)" " 2 (3.17%)"
"4" " 1 (1.59%)" " 1 (1.59%)"
"6" " 0 (0.00%)" " 0 (0.00%)"
G.2 p value
"63" ""
d1 "23.00 (19.50-28.00)" "0.483"
d1 "131.00 (120.00-156.00)" "<0.001"
d1 "3736.68±317.76" "<0.001"
d2 " " "<0.001"
"63 (100.00%)" " "
" 0 (0.00%)" " "
d2 " " "0.060"
" 6 (9.52%)" " "
"16 (25.40%)" " "
"41 (65.08%)" " "
d2 " " "0.037"
"45 (71.43%)" " "
"18 (28.57%)" " "
d2 " " "0.012"
"56 (88.89%)" " "
" 4 (6.35%)" " "
" 2 (3.17%)" " "
" 1 (1.59%)" " "
d2 " " "0.154"
"60 (95.24%)" " "
" 3 (4.76%)" " "
d2 " " "0.005"
"60 (95.24%)" " "
" 3 (4.76%)" " "
d2 " " "0.283"
"31 (49.21%)" " "
"20 (31.75%)" " "
" 9 (14.29%)" " "
" 0 (0.00%)" " "
" 2 (3.17%)" " "
" 1 (1.59%)" " " 设置有非正态资料
设置非正态后可以看到lwt变量是用百分位数进行描述,后边的pvalue也调用非参检验
tab2 <-scitb1(vars=allVars,fvars=fvars,strata=strata,data=data_neat, nonnormal=c("lwt")) Min 33.33333% 66.66667% Max
709.000 2598.000 3283.667 4990.000 Strata is treated as a continuous variable.tab2 Characteristic G.0 G.1
"N" "63" "63"
d1 "age" "22.00 (19.50-25.00)" "23.00 (19.00-28.00)"
d1 "lwt" "120.00 (105.00-131.00)" "120.00 (109.50-132.50)"
d1 "bwt" "2126.24±394.60" "2969.94±190.20"
d2 "low" " " " "
"0" " 4 (6.35%)" "63 (100.00%)"
"1" "59 (93.65%)" " 0 (0.00%)"
d2 "race" " " " "
"black" "12 (19.05%)" " 8 (12.70%)"
"other" "26 (41.27%)" "25 (39.68%)"
"white" "25 (39.68%)" "30 (47.62%)"
d2 "smoke" " " " "
"nonsmoker" "31 (49.21%)" "39 (61.90%)"
"smoker" "32 (50.79%)" "24 (38.10%)"
d2 "ptl" " " " "
"0" "45 (71.43%)" "58 (92.06%)"
"1" "16 (25.40%)" " 4 (6.35%)"
"2" " 2 (3.17%)" " 1 (1.59%)"
"3" " 0 (0.00%)" " 0 (0.00%)"
d2 "ht" " " " "
"0" "56 (88.89%)" "61 (96.83%)"
"1" " 7 (11.11%)" " 2 (3.17%)"
d2 "ui" " " " "
"0" "47 (74.60%)" "54 (85.71%)"
"1" "16 (25.40%)" " 9 (14.29%)"
d2 "ftv" " " " "
"0" "37 (58.73%)" "32 (50.79%)"
"1" "12 (19.05%)" "15 (23.81%)"
"2" " 8 (12.70%)" "13 (20.63%)"
"3" " 5 (7.94%)" " 2 (3.17%)"
"4" " 1 (1.59%)" " 1 (1.59%)"
"6" " 0 (0.00%)" " 0 (0.00%)"
G.2 p value
"63" ""
d1 "23.00 (19.50-28.00)" "0.483"
d1 "131.00 (120.00-156.00)" "<0.001"
d1 "3736.68±317.76" "<0.001"
d2 " " "<0.001"
"63 (100.00%)" " "
" 0 (0.00%)" " "
d2 " " "0.060"
" 6 (9.52%)" " "
"16 (25.40%)" " "
"41 (65.08%)" " "
d2 " " "0.037"
"45 (71.43%)" " "
"18 (28.57%)" " "
d2 " " "0.012"
"56 (88.89%)" " "
" 4 (6.35%)" " "
" 2 (3.17%)" " "
" 1 (1.59%)" " "
d2 " " "0.154"
"60 (95.24%)" " "
" 3 (4.76%)" " "
d2 " " "0.005"
"60 (95.24%)" " "
" 3 (4.76%)" " "
d2 " " "0.283"
"31 (49.21%)" " "
"20 (31.75%)" " "
" 9 (14.29%)" " "
" 0 (0.00%)" " "
" 2 (3.17%)" " "
" 1 (1.59%)" " " 连续变量快速分层描述
输出1可以看出年龄的自动分层记录,表明从14到20到25到45进行了分层
如果想要生成其它分层数,设置参数 num = n
# allvar删不删除年龄都可以
allVars3 <-c("race", "lwt","smoke", "ptl", "ht", "ui","ftv", "bwt")
fvars3 <-c("smoke","ht","ui","race")
strata3 <- "age"
tab3 <-scitb1(vars=allVars3,fvars=fvars3,strata=strata3,data=data_neat) Min 33.33333% 66.66667% Max
14 20 25 45 Strata is treated as a continuous variable.tab3 Characteristic G.0 G.1
"N" "51" "69"
d1 "lwt" "119.00 (106.00-135.00)" "121.00 (110.00-132.00)"
d1 "ptl" "0.00 (0.00-0.00)" "0.00 (0.00-0.00)"
d1 "ftv" "0.00 (0.00-1.00)" "0.00 (0.00-1.00)"
d1 "bwt" "2974.08±612.51" "2921.42±697.85"
d2 "smoke" " " " "
"nonsmoker" "28 (54.90%)" "44 (63.77%)"
"smoker" "23 (45.10%)" "25 (36.23%)"
d2 "ht" " " " "
"0" "48 (94.12%)" "64 (92.75%)"
"1" " 3 (5.88%)" " 5 (7.25%)"
d2 "ui" " " " "
"0" "43 (84.31%)" "58 (84.06%)"
"1" " 8 (15.69%)" "11 (15.94%)"
d2 "race" " " " "
"black" "10 (19.61%)" "10 (14.49%)"
"other" "18 (35.29%)" "27 (39.13%)"
"white" "23 (45.10%)" "32 (46.38%)"
G.2 p value
"69" ""
d1 "130.00 (115.00-153.00)" "0.086"
d1 "0.00 (0.00-0.00)" "0.171"
d1 "1.00 (0.00-2.00)" "0.011"
d1 "2945.13±839.82" "0.927"
d2 " " "0.587"
"43 (62.32%)" " "
"26 (37.68%)" " "
d2 " " "0.929"
"65 (94.20%)" " "
" 4 (5.80%)" " "
d2 " " "0.873"
"60 (86.96%)" " "
" 9 (13.04%)" " "
d2 " " "0.320"
" 6 (8.70%)" " "
"22 (31.88%)" " "
"41 (59.42%)" " " 保存结果
write.csv(tab0,file= "01-attch\\10\\data.csv",row.names = F,
fileEncoding = "gbk")保存出来是下图,复制到word改改就能用
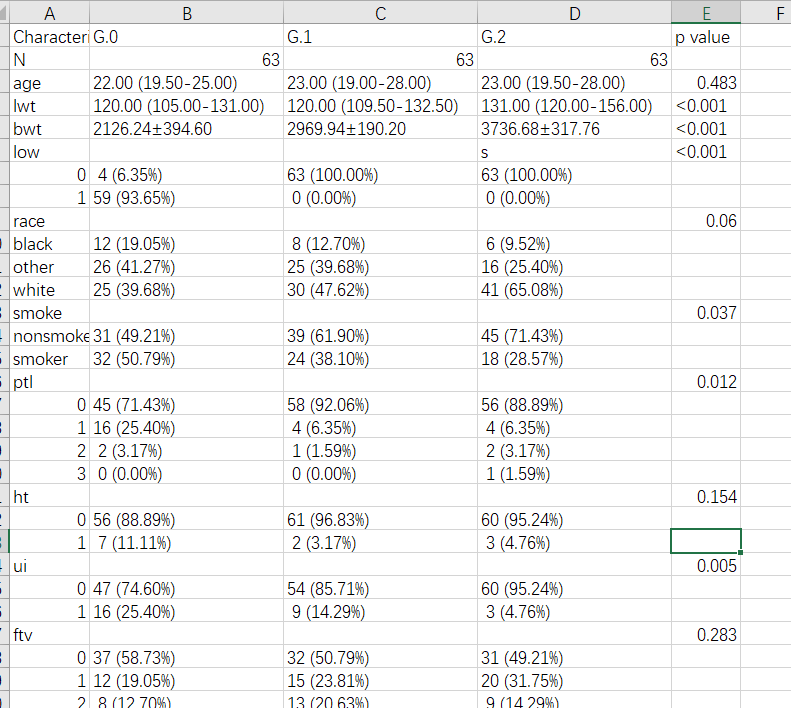
总结
使用体验:自定义度,结果展示等不如comparegroups,但是胜在参数简单,在期刊没那么高要求和平时展示可以用