library(bruceR)
library(purrr)
rm(list = ls())
# set_wd() # 自动构建时无需设置工作路径R语言批量导入数据
实用操作
数据导入
批量导入文件夹下的所有数据文件
以公开数据库CHRALS为例
在文件夹下有10个dta文件,文件名各不一致。如何将所有文件导入一个列表中?
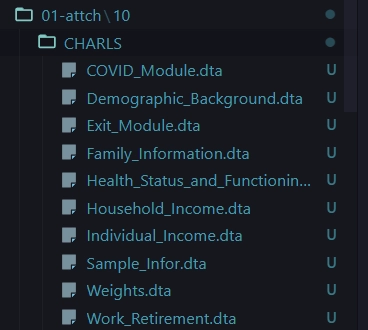
载入包
第一步:提取文件名
files <-
fs::dir_ls("01-attch\\10\\CHARLS",
recurse = TRUE,
glob = "*.dta")
print(files)01-attch/10/CHARLS/COVID_Module.dta
01-attch/10/CHARLS/Demographic_Background.dta
01-attch/10/CHARLS/Exit_Module.dta
01-attch/10/CHARLS/Family_Information.dta
01-attch/10/CHARLS/Health_Status_and_Functioning.dta
01-attch/10/CHARLS/Household_Income.dta
01-attch/10/CHARLS/Individual_Income.dta
01-attch/10/CHARLS/Sample_Infor.dta
01-attch/10/CHARLS/Weights.dta
01-attch/10/CHARLS/Work_Retirement.dta第二步:批量导入
data_list <- files |>
map(\(filename)
{import(file=filename)})可以看到已经导入成功 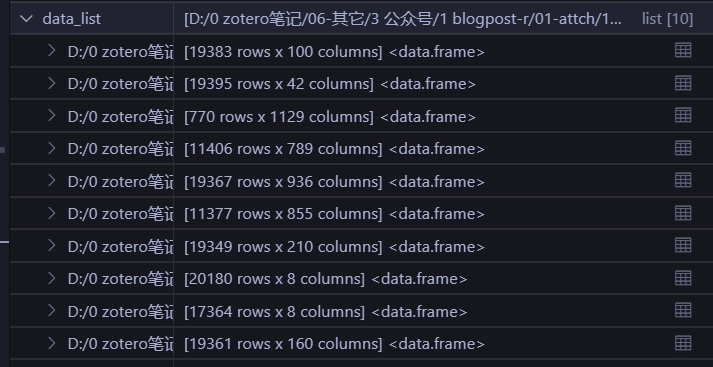
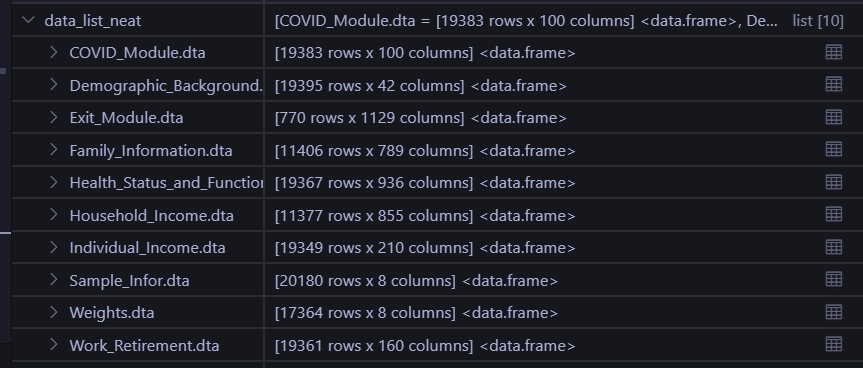
接下来美化一下
data_list_neat <- set_names(
data_list,
files |>
map(\(str)
{str_remove(str,
"01-attch/10/CHARLS/")})
)可以看到列表每个元素名也规范了
批量导入excel下的多个sheet
现在我们有一个excel文件,其中有多个sheet,如何一次性导入到列表里呢 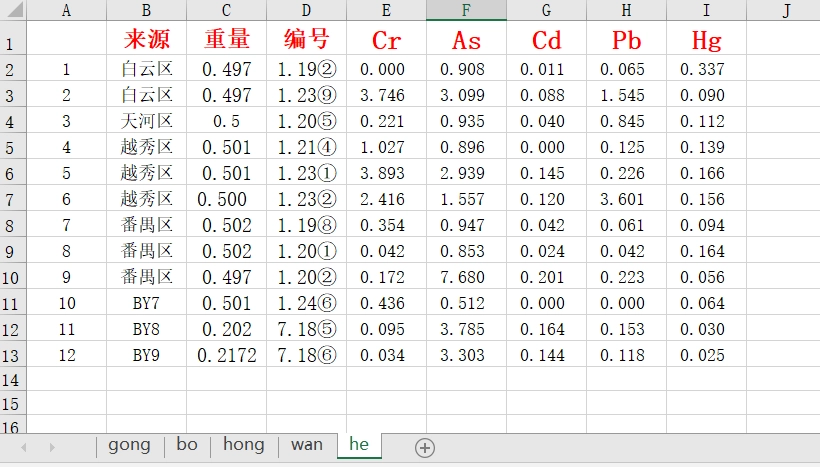
第一步:提取sheet名
sheet_names <- readxl::excel_sheets(
"01-attch/10/CHARLS/data.xlsx"
)
sheet_names[1] "gong" "bo" "hong" "wan" "he" 第二步:批量导入
data_list <-
sheet_names |>
map(\(var)
{import(
file='01-attch/10/CHARLS/data.xlsx',
sheet = var)
}) |>
set_names(sheet_names)New names:
New names:
New names:
New names:
New names:
• `` -> `...1`str(data_list)List of 5
$ gong:'data.frame': 12 obs. of 9 variables:
..$ ...1: num [1:12] 1 2 3 4 5 6 7 8 9 10 ...
..$ 来源: chr [1:12] "白云区" "白云区" "天河区" "天河区" ...
..$ 重量: num [1:12] 0.501 0.502 0.498 0.497 0.499 0.496 0.5 0.503 0.5 0.501 ...
..$ 编号: chr [1:12] "1.19④" "1.19⑨" "1.20⑦" "1.20⑧" ...
..$ Cr : num [1:12] 0.3465 0.1507 0.0616 0.0745 0.7903 ...
..$ As : num [1:12] 1.87 4.63 9.89 3.43 3.02 ...
..$ Cd : num [1:12] 0.0262 0.2018 0.4037 0 0.0485 ...
..$ Pb : num [1:12] 0.0761 0.2169 0.0744 0.131 0.4851 ...
..$ Hg : num [1:12] 0.1011 0.0577 0.187 0.1879 0.0538 ...
$ bo :'data.frame': 12 obs. of 9 variables:
..$ ...1: num [1:12] 1 2 3 4 5 6 7 8 9 10 ...
..$ 来源: chr [1:12] "白云区" "天河区" "天河区" "天河区" ...
..$ 重量: num [1:12] 0.501 0.496 0.499 0.504 0.5 ...
..$ 编号: chr [1:12] "1.19③" "1.20⑨" "1.20⑩" "1.21①" ...
..$ Cr : num [1:12] 0.0198 0.0384 0.0375 0.7255 1.784 ...
..$ As : num [1:12] 6.08 2.76 3.1 2.45 3.23 ...
..$ Cd : num [1:12] 0.0639 0.0788 0.0217 0 0.0549 ...
..$ Pb : num [1:12] 0.2474 0.0799 0.0743 0.0906 0.0836 ...
..$ Hg : num [1:12] 0.0362 0.0671 0.0383 0.0527 0.0442 ...
$ hong:'data.frame': 12 obs. of 9 variables:
..$ ...1: num [1:12] 1 2 3 4 5 6 7 8 9 10 ...
..$ 来源: chr [1:12] "白云区" "白云区" "天河区" "越秀区" ...
..$ 重量: num [1:12] 0.496 0.498 0.499 0.5 0.501 ...
..$ 编号: chr [1:12] "1.17②" "1.17④" "1.20⑥" "1.21⑩" ...
..$ Cr : num [1:12] 1.283 0.636 0.233 1.073 0.979 ...
..$ As : num [1:12] 5.57 2.56 2.15 4.8 3.21 ...
..$ Cd : num [1:12] 0.1119 0.0241 0.0224 0 0 ...
..$ Pb : num [1:12] 0.157 0.0256 0.0745 0.1524 0.356 ...
..$ Hg : num [1:12] 0.37 0.184 1.375 1.49 0.469 ...
$ wan :'data.frame': 12 obs. of 9 variables:
..$ ...1: num [1:12] 1 2 3 4 5 6 7 8 9 10 ...
..$ 来源: chr [1:12] "白云区" "白云区" "越秀区" "越秀区" ...
..$ 重量: num [1:12] 0.497 0.498 0.493 0.499 0.498 ...
..$ 编号: chr [1:12] "1.23⑦" "1.23⑧" "1.21⑤" "1.21⑥" ...
..$ Cr : num [1:12] 4.011 4.461 0.899 0.816 0.326 ...
..$ As : num [1:12] 0.0396 0.0934 0 0 1.4307 ...
..$ Cd : num [1:12] 0 0 0 0 0 0 0 0 0 0 ...
..$ Pb : num [1:12] 0 0.5965 0.0808 0.0878 0 ...
..$ Hg : num [1:12] 0.0066 0.017 0.062 0.0196 0.0404 0.0559 0.0074 0.0437 0.0177 0.0122 ...
$ he :'data.frame': 12 obs. of 9 variables:
..$ ...1: num [1:12] 1 2 3 4 5 6 7 8 9 10 ...
..$ 来源: chr [1:12] "白云区" "白云区" "天河区" "越秀区" ...
..$ 重量: num [1:12] 0.497 0.497 0.5 0.501 0.501 0.5 0.502 0.502 0.497 0.501 ...
..$ 编号: chr [1:12] "1.19②" "1.23⑨" "1.20⑤" "1.21④" ...
..$ Cr : num [1:12] 0 3.746 0.221 1.027 3.893 ...
..$ As : num [1:12] 0.908 3.099 0.935 0.896 2.939 ...
..$ Cd : num [1:12] 0.0115 0.0884 0.0395 0 0.1448 ...
..$ Pb : num [1:12] 0.065 1.545 0.845 0.125 0.226 ...
..$ Hg : num [1:12] 0.3371 0.0898 0.1123 0.1392 0.1663 ...尾语
本期主要使用了bruceR包和purrr包,基本可以满足日常数据导入的所有需求。